mar 20 2026
How to build an AirOps content writing workflow that can research, critique, and stay on brand
A practical model for turning AirOps into a real content writing system with research, self-critique, vector knowledge bases, brand guardrails, and release checks.
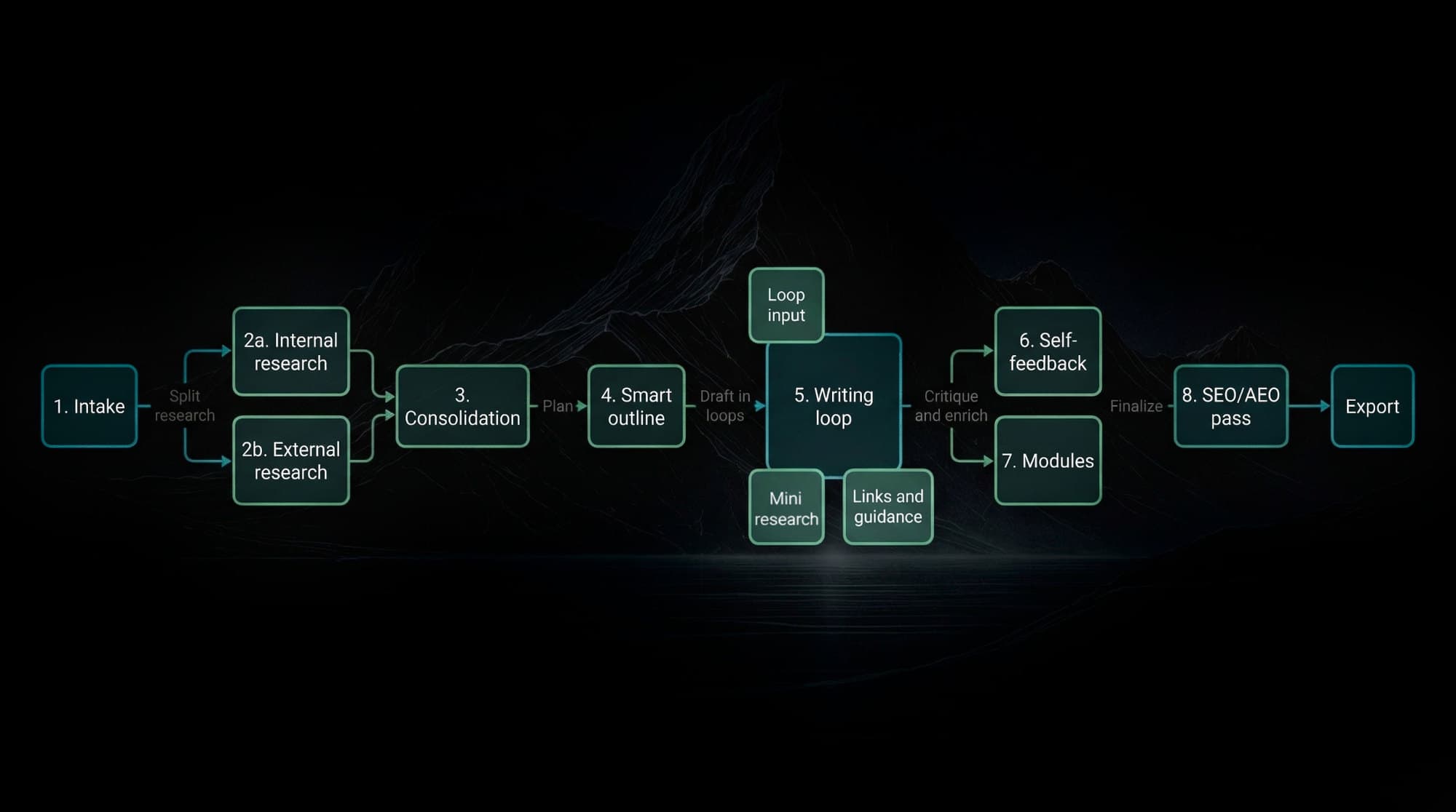
Workflow map
The full AirOps writing loop, from brief to publish-safe payload
The useful version is not one giant prompt. It is a staged system: split research lanes, consolidation, smart outlining, section-level drafting, self-critique, optional modules, and a final SEO and AEO pass.
Step 1
Intake contract
Start with a typed brief: topic, angle, length, audience, brand constraints, business intent, and any fixed requirements the workflow must honor.
Step 2A
Internal research
Pull from Brand Kits, vector knowledge bases, product truth, audience docs, prior posts, approved examples, and safe claim boundaries.
Step 2B
External research
Pull SERP patterns, query intent, primary docs, standards, community language, objections, and fresh supporting evidence.
Step 3
Research consolidation
Turn raw retrieval into one usable packet: source notes, claim support, internal and external link candidates, open questions, and query ideas for later drafting loops.
Step 4
Smart outline
Build the article structure from research plus user requirements. The outline should already know likely section depth, examples, artifacts, and where modules may be useful.
Step 5
Section writing loop
For each section: read the brief, generate procedural search queries, run mini-research for links or examples, draft the section, decide whether a richer block is needed, then save state for the next section.
Loop input
Mini research
The AI determines follow-up search queries procedurally based on gaps in the current section.
Loop state
Section memory
Earlier sections constrain later ones so the article does not repeat itself or drift.
Loop output
Links and guidance
Internal links, external citations, examples, and practical guidance are added during drafting, not bolted on at the end.
Step 6
Self-feedback
Critique for unsupported claims, brand drift, repetition, weak transitions, missing examples, and sections that are not answer-shaped enough to survive the final pass.
Step 7
MDX modules if applicable
Insert richer blocks only where the topic earns them: tables, checklists, comparison blocks, workbenches, or interactive modules.
Step 8
Final SEO and AEO pass
Check title, description, heading clarity, direct-answer structure, link coverage, metadata quality, markdown integrity, and publish safety before export.
Output
Export
Ship a publish-safe markdown payload.
What matters
The whole point is sequencing. Research feeds consolidation. Consolidation feeds the outline. The outline feeds section loops. Section loops feed self-critique. Only then do you run the final SEO and AEO pass.
How to build an AirOps content writing workflow that can research, critique, and stay on brand
Most AirOps writing workflows are still one polite prompt pointed at a pile of context.
That can work for demos. It falls apart the second you need consistency, brand control, research discipline, and outputs that do not need a full adult in the room every single time.
The fix is not "use a better prompt." The fix is to stop treating content writing like one generation event and start treating it like a system. In practice, that means a typed intake, retrieval against internal knowledge, structured section planning, self-critique, explicit brand guardrails, and a release path that can reject bad state before anything ships.
AirOps is actually a good environment for this when you use it correctly. Its Knowledge Bases let you store internal context and retrieve it semantically. Its Knowledge Base Search step returns chunks that are useful for drafting. Its Get Knowledge Base File step can pull full documents when the workflow needs source truth instead of just similar text. Its Brand Kits give you a centralized place to carry voice, product lines, content types, and audience-specific rules across workflows. Its Human Review step gives you a clean checkpoint when a human should actually intervene instead of playing permanent babysitter.
That stack maps pretty closely to the Deadwater writing workflow we built:
- Normalize the brief.
- Run internal and external research.
- Build an outline and section briefs.
- Draft sections with evidence attached.
- Run critique and QA passes.
- Export only if the output still obeys the contract.
If you have already read the anatomy of a reliable AI marketing workflow, what belongs in an AI knowledge base for marketing teams, and content quality assurance for AI pipelines, this is the AirOps implementation layer. The question is not whether AI can write. The question is whether the workflow can keep the writing grounded while it writes.
What does the full workflow actually look like?
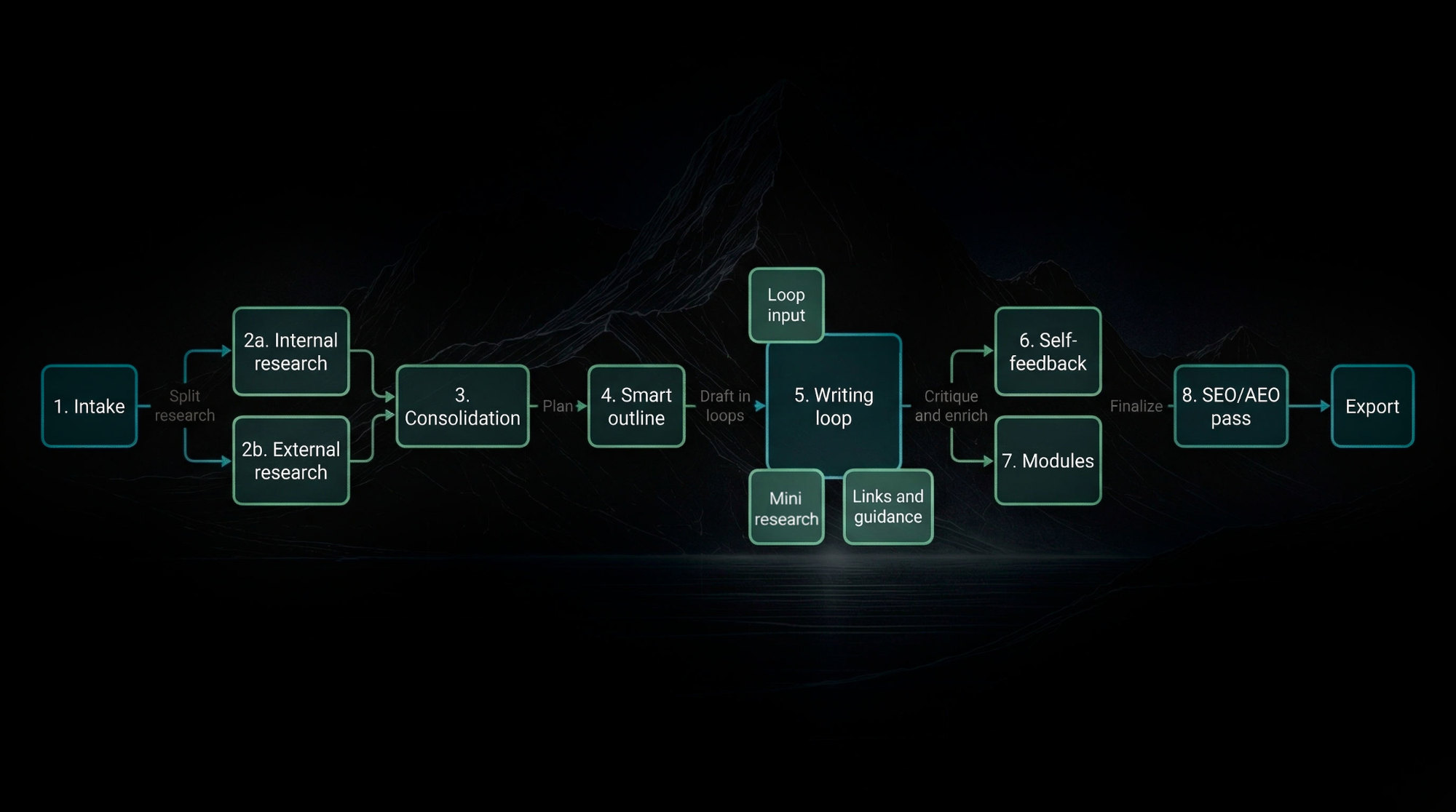
The useful version is staged, not monolithic
If you want an out-of-the-box writing workflow that can actually carry its own weight, the step order matters more than the prompting flourishes.
The practical sequence looks like this:
- Research internal context from vector knowledge bases and Brand Kits.
- Research external reality from the web, docs, and search results.
- Consolidate both into one usable research packet.
- Build a smart outline based on evidence, length, and input requirements.
- Draft section by section, not in one giant pass.
- Run a self-feedback loop that critiques and revises weak sections.
- Insert MDX-style modules or richer content blocks only where the topic benefits.
- Run a final SEO and AEO pass before export.
That is the map. The writing quality comes from how each stage constrains the next one.
Research should begin in two lanes
The first lane is internal. That means:
- Brand Kit rules.
- Product truth.
- Audience and positioning.
- Prior published posts.
- Offer boundaries and claims to avoid.
The second lane is external. That means:
- Search intent.
- SERP patterns.
- Primary-source citations.
- Community language.
- Current objections, confusion, and stale takes to avoid.
Those two lanes should stay separate long enough for the workflow to know what came from where. Internal retrieval tells the system how to speak and what is true about the business. External research tells it what is true in the market and which claims need proof.
Consolidation is where the workflow becomes usable
This step gets skipped constantly, and then people wonder why the draft feels like a bag of disconnected facts.
The workflow needs a consolidation pass that turns raw retrieval into a working packet:
- Section-relevant source notes.
- Claims with support attached.
- Internal link candidates.
- External link candidates.
- Open questions and weak evidence.
- Procedural query ideas for later section loops.
This is the point where the workflow stops being "RAG plus vibes" and starts becoming an editorial system.
The outline should be smart enough to control the draft
A good outline is not just headings. It should already know:
- The target depth.
- The likely word count by section.
- Which claims belong under each section.
- Which examples or artifacts the section should include.
- Where links, modules, or comparisons are likely to matter.
That means the workflow should use the research packet plus the user's requirements to determine the article shape. If the user wants a shorter tactical piece, the system should compress intelligently. If the user wants a long operator guide, the system should widen the section briefs and reserve space for examples, diagrams, and module slots.
Writing should happen in loops, not in one heroic generation
This is the real detail most people miss.
The writing stage should not just "write section two." It should do a mini execution loop:
- Read the section brief.
- Generate procedural search queries for missing details.
- Retrieve extra evidence or link targets if needed.
- Draft the section.
- Check whether the section wants a module, table, checklist, or workbench.
- Save state so the next section knows what has already been said.
That is how the workflow gets omni-capable without becoming sloppy. It can decide to pull a better citation, add one more comparison, or insert a richer content block exactly where the draft earns it.
The last mile should optimize for discoverability, not just cleanliness
Once the draft passes critique, the workflow still is not done.
The final pass should handle:
- SEO basics like title, description, heading clarity, and link coverage.
- AEO concerns like direct answerability, natural question phrasing, and section scannability.
- Publish safety like metadata integrity, markdown quality, and product-claim boundaries.
That final pass matters because a workflow can be directionally right and still ship a weak package. Search visibility, answer-engine fit, and clean export all live in the last mile.
What should the workflow do before it writes a single sentence?
Start with a contract, not a content request
The most common failure mode is still embarrassingly basic. Someone kicks off the workflow with "write a post about X," maybe adds a keyword, maybe adds a target audience, and then expects the rest of the system to reverse-engineer strategy from that mess.
That is not a workflow. That is a guessing machine with good manners.
The first object in the system should be a typed intake with fields the rest of the workflow can trust:
- Topic.
- Primary keyword.
- Angle.
- Search intent.
- Target reader.
- Business intent.
- Safe product boundaries.
- Must-cover internal context.
- Claims that require external support.
This is the same reason JSON Schema exists. Ambiguous interfaces create downstream chaos. Clear interfaces let later steps behave predictably. It is also why the intake object should behave more like the contract described in how to build AI content briefs that don't collapse in production than like a loose writing request.
For a writing workflow in AirOps, the intake should also decide which internal context lanes matter. Do you need product positioning? Audience pain? Style rules? Case-study constraints? Competitive language? If the workflow does not know that early, it will over-retrieve random context and under-retrieve the one document that actually mattered.
Keep internal context in separate vector knowledge bases
This is where a lot of teams get sloppy.
They build one giant knowledge base and pour everything into it: style guides, product notes, old blog posts, sales docs, transcripts, roadmap scraps, random PDFs, the whole digital landfill. Then they wonder why the workflow sounds vaguely informed and strangely confused at the same time.
Do not do that.
AirOps knowledge bases are useful precisely because you can organize and selectively retrieve context. The docs are explicit that you can upload files, web content, database material, and more, then retrieve what is most relevant by semantic similarity. That is helpful only if the corpus itself has some shape.
For a writing system, a better version-one architecture looks like this:
knowledge_bases:
brand_rules:
contains:
- Voice and tone guide
- Formatting rules
- CTA patterns
- Claims to avoid
product_truth:
contains:
- Offer descriptions
- Positioning docs
- Audience fit notes
- Approved differentiators
editorial_system:
contains:
- Writing workflow docs
- Brief templates
- QA checklists
- Publishing conventions
published_content:
contains:
- Prior blog posts
- Pillar pages
- Internal link targets
That separation matters because retrieval should be purpose-aware. If you are drafting a paragraph about offer framing, you probably want product_truth. If you are checking tone, you probably want brand_rules. If you are mining internal links, you probably want published_content. One huge shared bucket creates retrieval collisions you do not need.
This is also why vector systems need metadata, not just embeddings. AirOps' Knowledge Base Metadata docs show how to tag files by dimensions like region, product, audience, and content type, then filter retrieval at runtime. OpenAI's vector store file APIs do the same with file attributes and configurable chunking. The boring operational lesson is the same in both systems: context gets more useful when you can filter and scope it, not merely search it.
Brand Kits should sit above retrieval, not replace it
AirOps Brand Kits are not your knowledge base. They are your rules layer.
That distinction is important.
The knowledge bases tell the workflow what is true and where to find it. The Brand Kit tells the workflow how to speak, which content type it is writing, which audience it is targeting, and which rules override others. AirOps' Brand Kit usage docs are especially useful here because they show the hierarchy: global rules, then dimension-specific overrides like content type, audience, and region.
That means your workflow should not ask the model to "remember the brand." It should inject brand context explicitly at runtime and keep it separate from evidence retrieval.
That separation is one of the cleanest ways to avoid a surprisingly common failure mode: a workflow that confuses brand voice with factual support. Tone is not evidence. Product truth is not tone. Treating both as one blob is how you get confident copy that sounds right while saying the wrong thing.
How should research and retrieval actually run?
Internal retrieval and external research need different jobs
If your workflow is serious, it should research two worlds in parallel:
- Internal truth.
- External reality.
Internal truth comes from your vector knowledge bases and Brand Kit. That covers positioning, product details, style rules, historical content, and whatever operating context the system should inherit.
External reality comes from the open web: search results, standards, product docs, public language patterns, and evidence sources. This is where the workflow validates whether the angle is timely, whether the search intent is real, and whether any claims need stronger sourcing.
Google's guidance on helpful, reliable, people-first content still matters here. So does the basic architecture behind OpenAI file search, which combines retrieval before generation instead of pretending the model should improvise everything from pretraining alone. Different systems, same principle: generation quality depends heavily on what the model can access right now.
Retrieve for the section, not just the article
This is the difference between a workflow that produces substance and one that produces passable fog.
A lot of writing systems do one retrieval pass at the top, dump a bunch of context into the prompt, and hope the model will organize it. That is lazy architecture. It front-loads cost and still produces shallow sections because the retrieval is not aligned to the actual claim being written.
The stronger pattern is:
- Normalize the brief.
- Build the high-level outline.
- Generate section-specific research queries.
- Retrieve internal context per section.
- Pull external evidence per section.
- Draft with only the context that supports that section's job.
AirOps' Knowledge Base Search and Search Knowledge Base step are useful here because they return chunks rather than dumping whole archives into the context window. The trick is not merely searching. The trick is issuing better search inputs.
For example, instead of querying a knowledge base with brand voice, a section-level query might be:
Retrieve rules and examples relevant to writing a practical workflow article for technical marketers.
Prioritize strong opinions, short paragraphs, anti-generic framing, and safe product mentions.
That kind of query gives semantic retrieval something concrete to work with. It is also closer to how AirOps recommends using variables and testing queries rather than hard-coding generic search phrases.
Your workflow should build its own research packet
This is the part most "AI blog workflows" skip because it is not glamorous.
Before drafting, the workflow should assemble a working packet that records:
- Which internal sources were retrieved.
- Which external sources support specific claims.
- Which objections or stale angles showed up.
- Which internal posts are good link candidates.
- Which sections have weak evidence and need tighter claims.
That packet does not need to be user-facing. It does need to exist.
Without it, the workflow has no memory of why a claim belongs in section three, no way to tell whether a later critique is valid, and no legible artifact for debugging when the article drifts. It also makes self-feedback much worse because the critic model ends up reviewing prose without seeing the evidence base that prose was supposed to come from.
If you want the workflow to "do its own research," this is what that phrase should mean operationally: not random browsing, but structured evidence collection mapped to the draft plan.
It should also preserve future drafting instructions. Good research packets do not just contain facts. They contain execution hints:
- Which section needs a stronger example.
- Which concept deserves an internal link.
- Which query should be run again during the writing loop.
- Which section might benefit from a module instead of plain paragraphs.
That is how the writing stage gets smarter without getting looser.
How do you make the workflow critique itself without turning it into a debate club?
Split drafting from critique on purpose
The cleanest self-feedback loop is not one giant prompt that says "write this and then improve it." That usually produces tasteful mush.
You want separate stages with separate jobs:
- Drafter: writes the section from the brief and research packet.
- Critic: checks whether the section actually satisfies the brief, evidence requirements, and brand rules.
- Reviser: updates only the failing parts and preserves what already works.
This matters because the critic should not be trying to be creative. It should be trying to be annoying in the useful way. It should look for missing support, vague claims, tonal drift, repeated ideas, weak transitions, and violations of the brief contract.
That is much closer to software QA than to romantic ideas about writing.
Critique against explicit rubrics
If the feedback step is just "make this better," you have built a machine for endless subjective churn.
A better critic pass checks concrete rubrics such as:
- Does this section answer the brief's assigned question?
- Are material claims backed by retrieved internal or external sources?
- Does the section repeat a previous section?
- Does the tone match the Brand Kit and writing rules?
- Are product mentions accurate and bounded?
- Does the section include a concrete mechanism, example, or checklist?
- Does the section need a richer block like a table, checklist, or interactive module?
- Does the section create direct, answer-shaped language that will help with AEO later?
That is where Deadwater's own workflow maps well into AirOps. Our writing process already separates intake, research, section briefs, drafting, QA, and export. The self-feedback loop is just a stricter enforcement layer around those same contracts, and it solves a lot of the failure patterns behind the prompt brittleness tax.
You can express that inside the workflow as structured output instead of freeform notes:
{
"section_status": "revise",
"passes": [
"Matches target reader sophistication",
"Uses on-brand tone"
],
"fails": [
"Makes two unsupported claims about workflow reliability",
"Does not explain how vector knowledge bases are filtered",
"No internal link opportunity used"
],
"revision_instructions": [
"Add sourced explanation of metadata filtering",
"Replace generic reliability claim with mechanism",
"Link to the AI knowledge base article"
]
}
That shape makes the reviser less likely to destroy good sections while trying to fix one real problem.
Human review should be a risk checkpoint, not permanent life support
AirOps' Human Review step is useful, but only when you use it at the right moments.
If every draft always needs human rescue, the workflow is weak upstream.
If no draft ever gets human review, you are probably pretending low-risk and high-risk content are the same thing.
The practical middle ground is simple:
- Let the workflow self-critique and self-revise first.
- Route low-risk educational posts through release checks only.
- Route product-adjacent or claim-sensitive posts through human review.
- Route weird edge cases to a person early instead of letting the system improvise deeper into failure.
That is also more consistent with the NIST Generative AI Profile, which frames trustworthy AI operation around governance, monitoring, and risk-aware controls rather than magical autonomy theater. If you want the deeper policy layer behind that, it lines up closely with governance for agents.
Build this on a real Context OS
This post is one piece of the system. See how Deadwater structures source truth, workflows, and QA so AI-assisted work stays grounded.
How do guardrails and release checks keep the system from going sideways?
Guardrails should exist in layers
Teams love saying "brand guardrails" as if that means one prompt with a stern paragraph in it.
It does not.
Real guardrails live at multiple layers:
- Intake constraints.
- Brand Kit rules.
- Knowledge-base scoping.
- Section brief requirements.
- Critique rubrics.
- Release validation.
Each layer catches a different class of failure.
Intake constraints stop bad jobs from entering the system. Brand Kit rules keep tone and audience targeting coherent. Knowledge-base scoping prevents irrelevant retrieval. Section requirements force depth. Critique catches drift. Release validation blocks malformed or risky outputs from shipping.
Once you think this way, "staying on brand" stops being a vibes problem and starts being a system design problem.
Release checks should inspect the payload, not just the prose
A writing workflow should not end at "the article sounds good."
It should produce a publishable object with checks around:
- Title and description quality.
- Heading structure.
- Internal and external link coverage.
- Safe product language.
- Markdown shape.
- MDX or rich-module placement, if applicable.
- Answer-engine clarity for major sections.
- CTA alignment.
- Draft or publish status.
That is how you keep a decent draft from turning into a bad release.
One reason this matters more now is that vector-retrieval systems can feel grounded while still leaking bad assumptions. The article may quote the right style rules, use the right tone, and still carry stale offer framing because one outdated document made it into the retrieval path. A release check is where you catch that before the page becomes public.
Write back what the workflow learns
This part is underrated.
If your AirOps workflow finds a better objection framing, sharpens a style rule, or surfaces a missing internal document, that learning should not die inside one run. It should update the system.
AirOps' Write to Knowledge Base step makes that possible. The point is not to let the workflow spray half-baked thoughts into production knowledge. The point is to create controlled write-back lanes for approved artifacts:
- New approved article summaries.
- Updated objection libraries.
- Editorial QA findings.
- Fresh internal-link metadata.
That is where the workflow starts compounding.
The dead-simple architecture looks like this:
brief = normalize_input(input)
brand = load_brand_kit(input.content_type, input.audience, input.region)
internal = retrieve_internal_context(brief, scoped_knowledge_bases)
external = collect_external_research(brief)
packet = consolidate_research(internal, external)
outline = build_outline(brief, packet)
for section in outline.sections:
queries = generate_section_queries(section, packet)
section_context = retrieve_section_context(section, packet, queries)
draft = write_section(section, section_context, brand)
modules = choose_modules_if_applicable(section, draft)
critique = review_section(draft, brief, brand, section_context, modules)
if critique.status == "revise":
draft = revise_section(draft, critique, modules)
save(draft)
article = assemble_article()
qa = run_release_checks(article, brief, brand)
seo = run_seo_aeo_pass(article, brief)
if qa.status == "pass" and seo.status == "pass":
export(article, modules)
else:
route_to_review(qa, seo)
That is not sexy. It is also the difference between a workflow you can trust and a workflow you demo once and quietly stop using.
What changes when the AirOps workflow is built this way?
You stop babysitting prompts and start managing a system
That is the whole point.
The workload moves away from:
- Re-explaining the brand every run.
- Manually pasting context into prompts.
- Catching the same tone mistakes over and over.
- Fixing unsupported claims at the end.
And toward:
- Maintaining cleaner source truth.
- Improving retrieval scopes.
- Tightening critique rubrics.
- Expanding the release gates where failures keep appearing.
That is a much healthier use of human time.
The workflow gets better because its context gets better
This is one of the underrated advantages of vector knowledge bases when they are curated well. You are not just storing documents. You are shaping the context substrate the workflow depends on.
The better your internal context gets, the less the workflow needs heroic prompting. The cleaner your metadata gets, the less retrieval noise you fight. The sharper your Brand Kit gets, the less tone correction you need. The stricter your QA layer gets, the less human cleanup survives to the end.
In other words, the workflow improves the same way software systems improve: by tightening interfaces and reducing ambiguity, not by hoping the model wakes up inspired.
This is the practical path out of prompt-glue content ops
If you map our Deadwater writing workflow into AirOps, the steps are pretty clear:
- Intake object with typed fields.
- Scoped retrieval from vector knowledge bases.
- External research for reality checks and evidence.
- Research consolidation into a usable packet.
- Outline plus section-specific briefs.
- Drafting per section, with procedural mini-research loops.
- Critique and revision against explicit rubrics.
- Module insertion when the article benefits from richer blocks.
- SEO and AEO checks before export.
- Controlled write-back into internal knowledge when new truth is approved.
That is the real upgrade.
Not "AI writes our blog posts now."
More like: the system can research, draft, challenge itself, stay inside brand boundaries, and surface the places where a human actually matters.
That is a workflow.
If you want help designing that architecture in AirOps or deciding which parts belong in a fuller Context OS instead, book a scoping call.
Because the goal is not autonomous content theater. The goal is a writing system that can carry its own weight.
Ready to learn more?
Book a demo and we will walk you through what a governed Context OS could look like inside your stack.